

NVIDIA L40S는 기업이 성능, 효율성 및 ROI를 향상할 수 있도록 지원하고 AI, 그래픽 및 비디오 처리 애플리케이션에 강력한 성능을 제공하는 범용 컴퓨팅 솔루션입니다. L40S GPU는 다양한 기능을 통해 AI 워크로드를 가속화하는 최고의 플랫폼입니다. 생성적 AI를 위한 엔터프라이즈급 엔드투엔드 소프트웨어 플랫폼인 NVIDIA AI Enterprise와 산업 디지털화를 지원하는 NVIDIA Omniverse™ 플랫폼을 사용하면 가장 완벽한 솔루션을 얻을 수 있습니다.
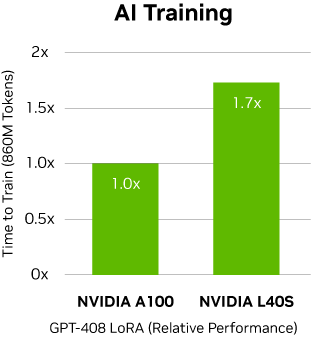
LoRA 미세 조정 (GPT-40B): 글로벌 훈련 배치(batch)
크기: 128 (시퀀스), 시퀀스 길이: 256 (토큰)
NVIDIA HGX™ A100 8-GPU 대 L40S GPU 4개가 탑재된
2개 시스템. 출시 전 빌드에서의 성능(변경될 수 있음)
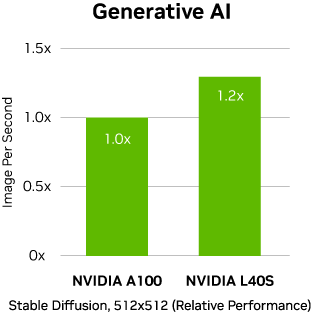
Stable Diffusion v2.1. 512 x 512 해상도 이미지
생성 시 상대적 속도 향상
NVIDIA HGX A100 8-GPU 대 L40S GPU 4개가 탑재된
2개 시스템. 출시 전 빌드에서의 성능(변경될 수 있음)
구조적 희소성 및 최적화된 TF32 형식에 대한 하드웨어 지원은 더 빠른 AI 및 데이터 사이언스 모델 트레이닝을 위한 기본 성능 향상을 제공합니다. DLSS로 AI 향상 그래픽 기능을 가속화하여 일부 애플리케이션에서 더 나은 성능으로 해상도를 업스케일링할 수 있습니다.
향상된 처리량과 동시 레이 트레이싱 및 음영 처리 기능이 레이 트레이싱 성능을 향상하여 제품 디자인 및 아키텍처, 엔지니어링, 건설 워크플로우를 위한 렌더링을 가속화합니다. 하드웨어 가속 모션 블러와 놀라운 실시간 애니메이션은 실제 같은 디자인을 구현합니다.
가속화된 단정밀도 부동 소수점(FP32) 처리량 및 향상된 전력 효율성은 3D 모델 개발 및 CAE(컴퓨터 보조 엔지니어링) 시뮬레이션과 같은 워크플로우의 성능을 크게 향상합니다. 혼합 정밀도 워크로드에는 향상된 16비트 연산 기능(BF16)을 사용합니다.
트랜스포머 엔진은 AI 성능을 획기적으로 가속화하고 훈련과 추론 모두에서 메모리 활용도를 개선합니다. Ada Lovelace 4세대 Tensor 코어의 강력한 성능을 활용하는 트랜스포머 엔진은 트랜스포머 아키텍처 신경망의 레이어를 지능적으로 스캔하고 FP8과 FP16 정밀도 사이에서 자동으로 리캐스트하여 더 빠른 AI 성능을 제공하고 학습 및 추론 속도를 높입니다.
L40S GPU는 엔터프라이즈 데이터센터의 24시간 운영에 최적화되었으며 최대의 성능, 내구성, 가동 시간을 보장하기 위해 NVIDIA에서 설계, 테스트, 구축, 지원합니다. L40S GPU는 최신 데이터센터 표준을 충족하고 네트워크 장비 구축 시스템(NEBS) 레벨 3을 지원하며, RoT(Root of Trust) 기술을 통한 안전한 부팅으로 데이터센터에 추가적인 보안 계층을 제공합니다.
L40S GPU는 NVIDIA DLSS 3를 통해 초고속 렌더링과 더 부드러운 프레임 레이트를 지원합니다. 이 획기적인 프레임 생성 기술은 딥 러닝과 4세대 Tensor 코어 및 광학 흐름 가속기를 포함하는 L40S GPU 및 Ada Lovelace 아키텍처의 최신 하드웨어 혁신을 활용하여 렌더링 성능을 높이고 더 높은 초당 프레임(FPS)을 제공하며 지연 시간을 크게 개선합니다.
| GPU 아키텍처 | NVIDIA Ada Lovelace 아키텍처 |
| GPU 메모리 | 48GB GDDR6(ECC 포함) |
| 메모리 대역폭 | 864GB/s |
| 인터커넥트 인터페이스 | PCIe Gen4 x16: 양방향 64GB/s |
| NVIDIA Ada Lovelace 아키텍처 기반의 CUDA® 코어 | 18,176 |
| NVIDIA 3세대 RT 코어 | 142 |
| NVIDIA 4세대 Tensor 코어 | 568 |
| RT 코어 성능 TFLOPS | 212 |
| FP32 TFLOPS | 91.6 |
| TF32 Tensor 코어 TFLOPS | 183 I 366* |
| BFLOAT16 Tensor 코어 TFLOPS | 362.05 I 733* |
| FP16 Tensor 코어 | 362.05 I 733* |
| FP8 Tensor 코어 | 733 I 1,466* |
| 최대 INT8 Tensor TOPS 최대 INT4 Tensor TOPS |
733 I 1,466* 733 I 1,466* |
| 폼 팩터 | 4.4"(H) x 10.5"(L), 듀얼 슬롯 |
| 디스플레이 포트 | DisplayPort 1.4a 4개 |
| 최대 소비 전력 | 350W |
| 전원 커넥터 | 16핀 |
| 열처리 | 수동 |
| 버츄얼 GPU(vGPU) 소프트웨어 지원 | 예 |
| vGPU 프로파일 지원 | 버츄얼 GPU 라이선싱 가이드 보기 |
| NVENC I NVDEC | 3x | 3x (AV1 인코딩 및 디코딩 포함) |
| RoT(Root of Trust)를 통한 안전한 부팅 | 예 |
| NEBS 지원 | 레벨 3 |
| MIG(Multi-Instance GPU) 지원 | 아니요 |
| NVIDIA® NVLink® 지원 | 아니요 |
|
*희소성 포함 |
|